
伴隨著“中國制造”,“中國創(chuàng)造”走向世界,漢之光華將以卓越的
服務(wù)能力協(xié)助我們的客戶完成全球知識產(chǎn)權(quán)布局。



來源: 發(fā)布時間:2025-04-18 11:08 點(diǎn)擊量:635
【前 言】
2024年7月,世界知識產(chǎn)權(quán)組織WIPO發(fā)布了《生成式人工智能專利態(tài)勢報告》(以下簡稱:WIPO報告),報告分析了從2014年至2023年底的十年間,全球生成式人工智能(GenAI)相關(guān)專利情況,并給出了權(quán)威的結(jié)論。WIPO報告顯示,在這10年間,全球GenAI相關(guān)專利申請有5.4萬件,其中中國的專利申請量以3.8萬件占據(jù)首位,遠(yuǎn)遠(yuǎn)超過美國、韓國、日本和印度等國。由于 GenAI 技術(shù)呈現(xiàn)井噴式發(fā)展,相應(yīng)的專利申請量也呈現(xiàn)指數(shù)式上升,僅2023年公布的 GenAI 相關(guān)專利就超過了全部總數(shù)的1/4。相應(yīng)地,GenAI技術(shù)淘汰速度也非常快,可以想見過去10年的專利技術(shù),越是新的技術(shù)越是具有參考借鑒價值。
本文將沿襲WIPO報告的專利分析思路,聚焦ChatGPT發(fā)布后幾個重要的國外公司公開的相關(guān)專利,即2023年1月以后公開的相關(guān)專利,進(jìn)行相關(guān)專利數(shù)據(jù)分析,為感興趣的客戶提供參考。
一、OpenAI的專利公開情況
由于ChatGPT產(chǎn)品的成功,在公眾心目中 OpenAI 即 GenAI。因此OpenAI公司是我們必須首先研究一下的研發(fā)主體。
OpenAI公司初創(chuàng)于2015年。2017年“情緒神經(jīng)元”和 OpenAIFive 項(xiàng)目的突破,使得OpenAI開始關(guān)注大型語言模型(LLM)。2019年7月,微軟(Microsoft)宣布與OpenAI開展為期多年的合作。微軟投資OpenAI 10億美元,雙方攜手合作替Azure云端平臺服務(wù)開發(fā)人工智能技術(shù)。微軟也成為OpenAI的獨(dú)家云供應(yīng)商和 OpenAI 新AI技術(shù)商業(yè)化的首選合作伙伴。微軟的加持使得OpenAI的大模型開發(fā)如虎添翼。之后,OpenAI 公司為整個行業(yè)提供了日新月異的創(chuàng)新成果,引領(lǐng)著行業(yè)的方向。
然而,經(jīng)過嚴(yán)格的專利檢索發(fā)現(xiàn),以“OPENAI OPCO LLC”作為專利申請人申請的專利非常少,真正有效的專利申請是從2023年開始的;截至本文發(fā)表日,僅有28個專利同族公開。在2023年前,OpenAI公司沒有通過專利申請去保護(hù)其任何研究成果。當(dāng)然,OpenAI 公司創(chuàng)立伊始是一個非營利性的研究機(jī)構(gòu),其研究成果往往通過學(xué)術(shù)論文的方式公開。同時0penAI公司最初將其重要的代碼開源,以活躍各技術(shù)方向在全球的研發(fā)活動。同時,OpenAI也可能正在通過商業(yè)機(jī)密的形式保護(hù)其知識產(chǎn)權(quán)。不過由于最前沿的技術(shù)不得不公開以加速其全球的研發(fā),同時又要維護(hù)OpenAI公司在該技術(shù)上的專屬權(quán)以獲得相應(yīng)的經(jīng)濟(jì)回報,反哺其研發(fā)活動,使得其研發(fā)具有可持續(xù)性。因此對其研發(fā)成果進(jìn)行專利申請,恰恰是最好公司利益的保護(hù)方式。
我們欣喜地看到,自從2022年底ChatGPT產(chǎn)品發(fā)布后,OpenAI公司開始了專利申請。基于現(xiàn)在有限的專利申請量,我們僅能總結(jié)出以下一些結(jié)論,相信隨著更多的專利公開,我們將會得到更多有價值的結(jié)論。
第一:OPENAI 專利的技術(shù)構(gòu)成
根據(jù) OPENAI 專利的IPC分類號統(tǒng)計(jì),可以得出以下申請量排名領(lǐng)先的技術(shù)構(gòu)成。根據(jù)該技術(shù)構(gòu)成排名,可以認(rèn)為,OPENAI公司的創(chuàng)新主要圍繞自然語言處理展開的。
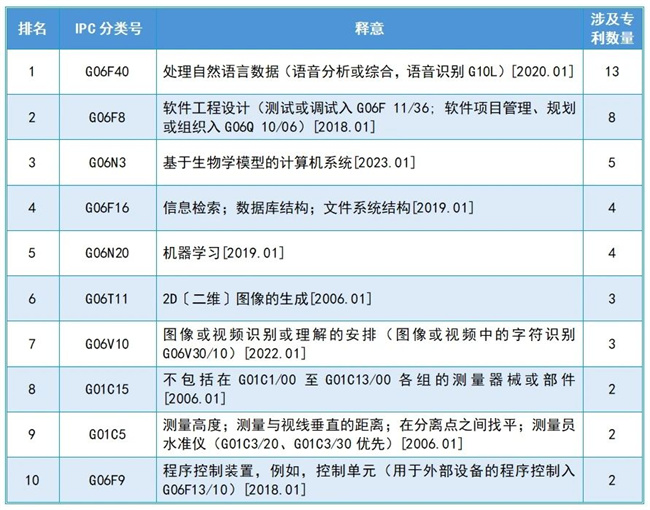
第二:專利受理局
在我們調(diào)研的28個專利同族中,都在美國有專利申請,其中僅有4件專利有PCT申請,但未見在任何國家落地。可見 OPENAI 公司的專利保護(hù)策略還是局限于美國原研地。可見其專利技術(shù)還是聚焦基礎(chǔ)技術(shù),在亞洲地區(qū)非常活躍的有關(guān)具體應(yīng)用的技術(shù)方案,OPENAI尚未涉及;當(dāng)然也可以理解為,OPENAI公司鼓勵亞洲各研發(fā)實(shí)體應(yīng)用其開發(fā)的基礎(chǔ)專利,來設(shè)計(jì)具體的應(yīng)用產(chǎn)品。
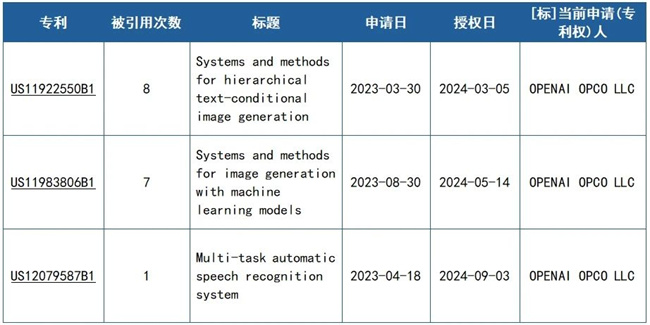
第三:專利被引用
專利被引用次數(shù)是一個非常好的指標(biāo),其可以識別哪些專利技術(shù)已被廣泛應(yīng)用,并且說明有很多研發(fā)人員已經(jīng)借鑒過這些技術(shù)。被引用次數(shù)越多的專利,其影響力越大,甚至可以代表該技術(shù)領(lǐng)域的核心創(chuàng)新技術(shù)。據(jù)統(tǒng)計(jì),OPENAI有以下3篇專利被引用,這3篇專利,都是2023年申請的,并都于2024年獲得授權(quán)。可以預(yù)見,隨著各國 GenAI 相關(guān)應(yīng)用技術(shù)的發(fā)展,將會有更多OPENAI 申請的基礎(chǔ)專利被引用。
二、其他國外知名公司的專利公開情況
GenAI各主要大模型的專利公開量
相較于OPENAI公司很少的專利公開量,很多其他國外知名公司卻有更多的相關(guān)專利公開量。根據(jù)《WIPO報告》里面全球?qū)@_量的排名,排名第5的IBM、第8的Alphabet/Google、第10的Microsoft和 第19的Adobe是 GenAI 領(lǐng)域?qū)@易遄疃嗟拿绹尽BM 開發(fā)了一個 GenAI 平臺 watsonx,該平臺使公司能夠使用和定制 LLM,重點(diǎn)關(guān)注數(shù)據(jù)安全性和合規(guī)性,因?yàn)楣究梢詷?gòu)建基于自己數(shù)據(jù)訓(xùn)練的 AI 模型(Stack Overflow 2023)。Alphabet 的 AI 部門 DeepMind 最近推出了其最新的 LLM 模型 Gemini,該模型最終將集成到 Google 的搜索引擎、廣告產(chǎn)品、Chrome 瀏覽器和其他產(chǎn)品中(Pichai 和 Hassabis 2023)。Microsoft是 GenAI 的主要參與者,不僅是因?yàn)槠鋵?OpenAI 的大量投資,該公司還大量投資了其他研究活動。例如,Microsoft在2024年投資了InnerEye 項(xiàng)目,該項(xiàng)目分析醫(yī)學(xué)掃描以檢測異常、診斷疾病并推薦治療方案。
我們研究了《WIPO報告》里面排名靠前的美國公司IBM、Google、Microsoft、Adobe、以及GAN申請量非常多的德國知名企業(yè)Siemens和韓國SamSung。通過研究這幾個排名靠前的國外知名公司在ChatGPT發(fā)布前后(即2023年前后)的相關(guān)專利公開量,并且根據(jù)GenAI各主要大模型加以梳理,形成以下柱狀圖,直觀地展示了IBM、SamSung、Google、Microsoft、Adobe、Siemens 等公司,于2023年前后在GAN,VAE,LLM,AE,DM 大模型上相關(guān)專利公開量。
注——
1.2023年前是指:2014年1月1日~2022年12月31日;2023年后是指:2023年1月1日~2024年6月30日。我們將2024年6月30日作為專利統(tǒng)計(jì)的截?cái)嗳眨饕且驗(yàn)橛泻芏?024年下半年申請的專利尚未公開
2.各大模型具體的含義:
生成對抗網(wǎng)絡(luò) Generative adversarial networks (GAN)
變分自編碼器 Variational autoencoders (VAE)
基于解碼器的大型語言模型 decoder-based large language models (decoder-based LLM)
自回歸模型 Autoregressive models(AM)
擴(kuò)散模型 Diffusion models(DM)
各大模型的技術(shù)特點(diǎn)詳見:《生成式人工智能(GenAI+)最新專利技術(shù)發(fā)展態(tài)勢系列之一——-GenAI+大模型》
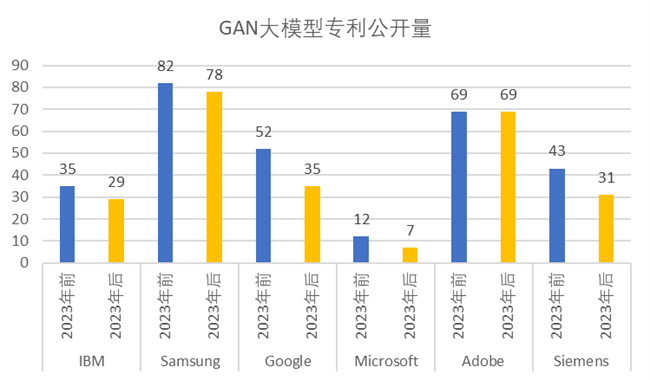
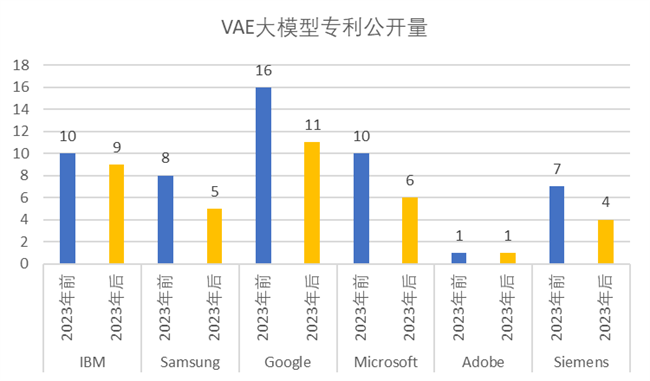
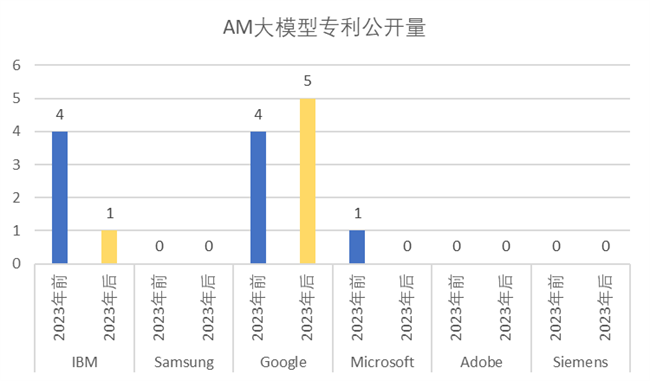
從各大公司的 GAN、VAE、AM 大模型相關(guān)專利的申請情況來看,2023年后的專利申請量沒有明顯的爆發(fā)性上升,這個情況和三個大模型在總體上受到 ChatGPT 發(fā)布的影響較小的結(jié)論是一致的。
在各大公司中僅有Microsoft公司在GAN大模型的專利申請量較少,Adobe公司在VAE大模型的相關(guān)專利上產(chǎn)出很少。
從總體上而言,AM 大模型相關(guān)專利一直只有零星的申請量。落實(shí)到各大知名公司上,僅有Google公司在2023年前后都有相關(guān)專利申請;IBM公司在2023年后的相關(guān)專利申請明顯下降;其他知名國外公司則在 AM 大模型上未見相關(guān)專利申請。可以預(yù)見,若沒有新應(yīng)用場景的涌現(xiàn),AM大模型相關(guān)專利將延續(xù)現(xiàn)在的零星的申請量,甚至將不會有研發(fā)實(shí)體再繼續(xù)這方面的應(yīng)用研究投入。
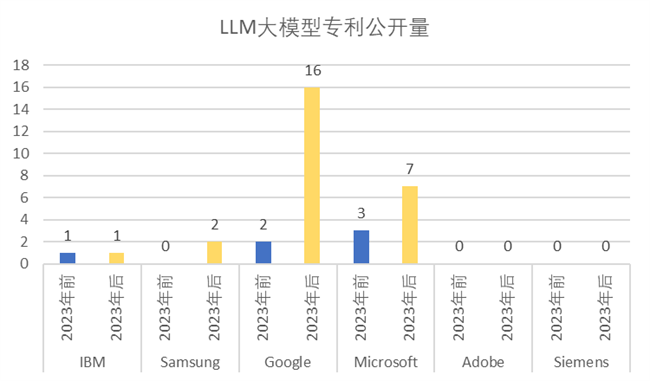
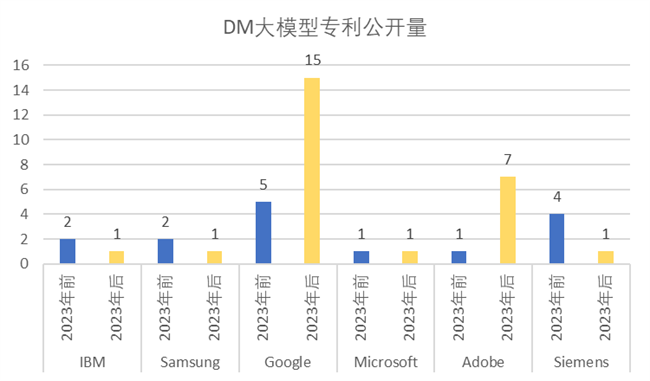
相較于GAN、VAE、AM 大模型,各大國際知名公司的 LLM 和 DM 大模型的則在2023年前后受到ChatGPT 的影響非常大。尤其是LLM 大模型,Google 和 Microsoft 公司在2023年后相關(guān)專利申請量成倍數(shù)增加,顯然這和這兩家公司同OPENAI公司的合作密切相關(guān)。
以上的專利統(tǒng)計(jì),是基于專利標(biāo)題、摘要以及權(quán)利要求等信息,進(jìn)行的專利類型歸類。但是,所有GenAI專利家族中有很大一部分不適合任何特定的大模型。許多GenAI專利的標(biāo)題、摘要以及權(quán)利要求不包含特定的大模型關(guān)鍵字,而是專注于描述專利的應(yīng)用,并且在專利說明書里面只對使用的GenAI過程進(jìn)行了一般性描述。這使得我們很難將一些專利映射到五個核心GenAI模型,同時這5種不同的大模型在技術(shù)解決方案上也有一些重疊。因此以上的統(tǒng)計(jì)不免有些失真的情況,但是從總體上而言還是有說服力的。
根據(jù)《WIPO報告》顯示,真正活躍的GenAI大模型的研發(fā)實(shí)體,其實(shí)在中國。之后我們將研究中國的各大研發(fā)實(shí)體對GenAI應(yīng)用的貢獻(xiàn)。敬請期待!

微信公眾號

官網(wǎng)移動端



